一个关键词 18 万 ! AI 搜索已经被这帮人玩坏了
一个关键词 18 万 ! AI 搜索已经被这帮人玩坏了昨天晚上闲着没事,想在 DeepSeek 搜一下 AI 博主有哪些可以学习的。 结果没想到,搜索结果里竟然出现了我自己。 内心 OS:祖坟冒青烟了,妈妈我出息了,我被 AI 认证了,以后简历可以写被
来自主题: AI资讯
10490 点击 2025-10-22 10:10
 搜索
搜索
昨天晚上闲着没事,想在 DeepSeek 搜一下 AI 博主有哪些可以学习的。 结果没想到,搜索结果里竟然出现了我自己。 内心 OS:祖坟冒青烟了,妈妈我出息了,我被 AI 认证了,以后简历可以写被

在今年 3 月 DeepSeek 和豆包占领国内产品月活用户增速前两名的时候,以第三姿态紧随其后的,是红果短剧。两者之间这个巧合的「偶遇」,意外也不意外。反映的正是我们当下经历的最重要的技术与文化浪潮。
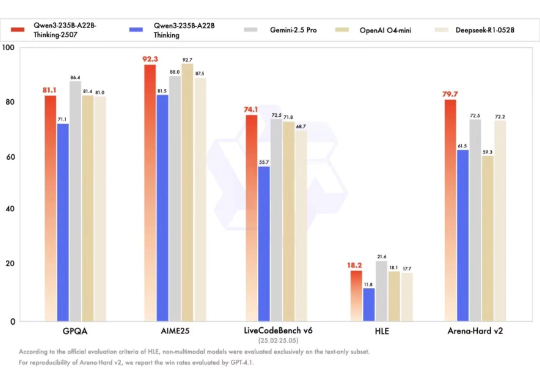
2025 年 9 月 19 日,亚马逊云科技官宣:Qwen3 和 DeepSeek v3.1,首次上线 Amazon Bedrock ,正式对外提供服务,再一次引起了全球生成式 AI 市场对 Amazon Bedrock 这一产品的关注。
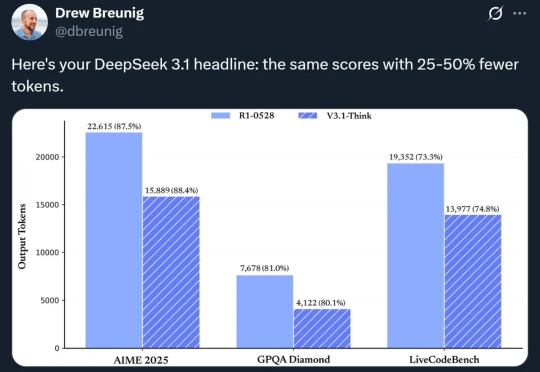
在最近的一档脱口秀节目中,演员张俊调侃 DeepSeek 是一款非常「内耗」的 AI,连个「1 加 1 等于几」都要斟酌半天。
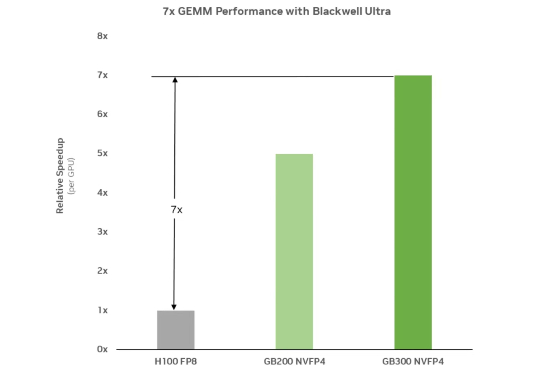
前些天,DeepSeek 在发布 DeepSeek V3.1 的文章评论区中,提及了 UE8M0 FP8 的量化设计,声称是针对即将发布的下一代国产芯片设计。
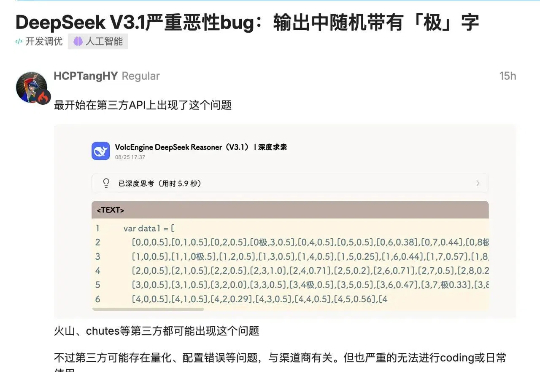
一早起来,看到群里炸了锅!主角是我们备受期待的 DeepSeek V3.1 模型。有用户反馈,该模型在生成文本时,会毫无征兆地随机插入“极”这个汉字(繁体简体都会)

今天下午,DeepSeek 官方正式发布 DeepSeek-V3.1。相比于前天只在用户群里通知,今天新增了模型升级点、榜单成绩、model card,huggingface 上现在也可以下载模型文件了。
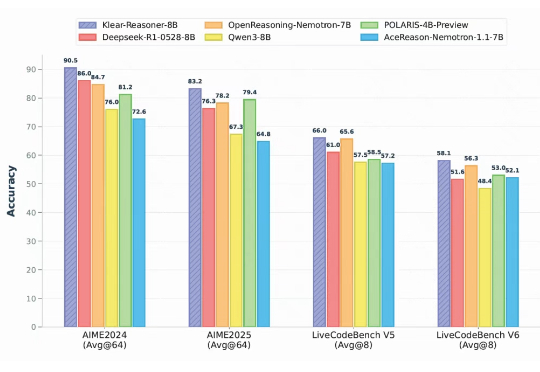
在大语言模型的竞争中,数学与代码推理能力已经成为最硬核的“分水岭”。从 OpenAI 最早将 RLHF 引入大模型训练,到 DeepSeek 提出 GRPO 算法,我们见证了强化学习在推理模型领域的巨大潜力。
软件+硬件的全链路国产 AI 体系来了? 这几天,不论国内国外,人们都在关注 DeepSeek 发布的 V3.1 新模型。

这就是我与 HMD 3210 的奇遇记:一台外表是 30 年前诺基亚、内心却住着一个完整大模型的「时光机器」。